
![]() Hace más de dos años (allá por Enero 2014, cómo pasa el tiempo!!) publicamos la 1ª parte del artículo sobre los REQUISITOS HARDWARE de NX NASTRAN (I) donde explicábamos los aspectos básicos de la configuración hardware de NX NASTRAN en general, así como los detalles específicos para utilizar el solver con el pre&postprocesador FEMAP. Pues bien, en este artículo vamos a avanzar un poco más y aprender cómo configurar tanto a nivel de hardware como de software del Sistema Operativo (SO) Windows con el objetivo de mejorar el rendimiento y las prestaciones del solver de Análisis por Elementos Finitos NX NASTRAN para dar respuesta al reto de incremento continuado del tamaño del modelo de Elementos Finitos (EF) que año tras año sigue aumentando de forma irremediable:
Hace más de dos años (allá por Enero 2014, cómo pasa el tiempo!!) publicamos la 1ª parte del artículo sobre los REQUISITOS HARDWARE de NX NASTRAN (I) donde explicábamos los aspectos básicos de la configuración hardware de NX NASTRAN en general, así como los detalles específicos para utilizar el solver con el pre&postprocesador FEMAP. Pues bien, en este artículo vamos a avanzar un poco más y aprender cómo configurar tanto a nivel de hardware como de software del Sistema Operativo (SO) Windows con el objetivo de mejorar el rendimiento y las prestaciones del solver de Análisis por Elementos Finitos NX NASTRAN para dar respuesta al reto de incremento continuado del tamaño del modelo de Elementos Finitos (EF) que año tras año sigue aumentando de forma irremediable:
- En 2004 un tamaño de 1.2 millones de GDL se consideraba un modelo grande.
- En 2011 un tamaño de modelo de 10 a 20 millones de GDL era un tamaño típico en muchos modelos de EF.
- En 2016 se estima manejar tamaños de modelos de EF entre 30 a 50 millones de GDL de forma habitual.
Para solucionar el reto del tamaño del modelo de EF tendremos que:
- Seleccionar el hardware y SO (Sistema Operativo) correcto.
- Utilizar el hardware de forma eficiente, incluyendo el ajuste de parámetros del SO.
- Usar de forma apropiada los “NX Nastran Keywords & Parameters“.
- Aprovechar la capacidad de procesado en paralelo de NX NASTRAN.
- Seleccionar métodos de solución adecuados para reducir el tiempo de cálculo.
Selección de Hardware y SO
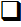 Procesador:
Procesador:
- Cuanto más rápido mejor, por supuesto.
- Pero además la clave está en la cantidad de memoria caché del procesador, cuanta más mejor, y esto la gente no lo valora en general. Aquí tienes algunos ejemplos de procesadores del mercado:
- Intel Core i7 de 6ª generación (Skylake) varía entre 4 y 8 MB de caché y 2 canales de memoria.
- Intel Core i7 Extreme Edition varía entre 10 y 20 MB de caché y 4 canales de memoria.
- Intel Xeon E5 v3 varía entre 10 y 35 MB de caché, y de 3 a 4 canales de memoria.
- Intel Xeon E7 v3 varía entre 20 y 45 MB de caché, con 4 canales de memoria.
- Preferible usar procesadores con múltiples núcleos, cuantos más mejor.
- Se rumorea que en Octubre de 2016 AMD va a sacar una nueva generación de procesadores fabricados en 14 nm con una arquitectura completamente nueva llamada Zen y con 8 núcleos físicos que supondrá un cambio radical con los actuales procesadores Intel. Tendrá un TDP de 95W, lo cual no está nada mal (su competidor directo, el Intel Core i7-5960X con CPU de 8 núcleos, arroja un TDP de 140W, además de estar fabricado en una litografía de 22nm). Se especula que su socket sea el fm3 con soporte DDR4.

Memoria RAM:
- La memoria RAM en procesos de cálculo es clave, recomiendo instalar toda la memoria RAM que admita el ordenador: si no hay RAM suficiente de nada vale la potencia del procesador. La memoria que no use el solver NX NASTRAN será utilizada por el SO para caché de I/O, reduciendo así el tiempo de cálculo
- Hace varios años un ordenador con 32 GB de RAM era una máquina realmente potente, pero en la actualidad es muy poco, recomiendo al menos instalar 64 GB de RAM, es lo mínimo!!.
- Ya tenemos en el mercado disponible la nueva generación de portátiles Skylake que admiten hasta 64 GB de RAM DDR4, impresionante (ya queda menos para comprar el mío!!). Y en WorkStations instalar 128 GB de RAM ya es de lo más habitual.
- La nueva generación de procesadores Intel con tecnologías HASWELL y SKYLAKE soportan memoria RAM DDR4 cuya ventaja más representativa (frente a la vieja DDR3) es el incremento de la frecuencia del reloj unido a un menor voltaje de funcionamiento (por tanto menor generación de calor), lo cual proporciona un mayor rendimiento, cuantificado (según algunos fabricantes) en un 50% de mejora.
Disco:
- El uso de discos “profesionales” SSD (Solid State Drive) supone una ganancia brutal en prestaciones ya que no tiene partes mecánicas, son sólidos, y se caracterizan por una alta velocidad de transferencia de datos (¡¡10 veces!! más rápido que un disco duro mecánico convencional) y unos tiempos mínimos de acceso a la información (además desprenden menos calor al alcanzar menos temperatura y no hacen absolutamente ningún ruido). A mayor I/O, menor tiempo de cálculo.
- La velocidad de transferencia de un disco duro mecánico de 7200 rpm suele ser de 100 a 150 MB/s, mientras que un SSD “doméstico” con interfaz SATA3 llega fácilmente a los 550 MB/s.
- El nuevo formato M.2 con conexión PCI-Express 3.0 x4 NVMe (por ejemplo, el Samsung SSD 950 PRO 512GB M.2) alcanza velocidades de transferencia de 2500 MB/s, es decir, casi 5 veces más rápido que un SSD normal!!. El factor de forma M.2 es de reciente creación ya que ha llegado al mercado con el chipset Z97 de Intel, pero su uso irá en aumento en los próximos meses ya que substituirá por completo al formato mSATA.
- Es preferible montar una WorkStation con múltiples discos (1 + 4): un disco SSD para el sistema operativo (que arrancará en menos de 10 segundos) y cuatro discos SSD en configuración RAID-0 (Disk Stripping) para el espacio de SCRATCH de NX Nastran.
- Por ejemplo, ahora que los precios de los discos SSD han bajado bastante recomiendo montar un RAID-0 con 4 discos SSD de 256 GB para tener una unidad [D:] con 1 TB donde establecer el directorio D:\SCRATCH.
- Es importante establecer siempre el directorio SCRATCH de NX NASTRAN en un disco físico separado de la unidad del SO [C:]. No sólo una partición distinta, sino un disco físico distinto. Se recomienda hacer lo mismo con el directorio temporal D:\TEMP.
- Una segunda buena alternativa es montar un RAID-0 con discos SAS de 15K RPM que son más rápidos y más fiables que los discos SATA, y además consumen menos energía que los discos SATA. Pero para mí la opción SSD es la más eficiente, no hay color!!.
GPU e Intel MIC
- El GPU COMPUTING o cálculo acelerado en la GPU puede definirse como el uso de una unidad de procesamiento gráfico (GPU) en combinación con una CPU para acelerar aplicaciones de cálculo científico. Ofrece un rendimiento elevado ya que traslada las partes de la aplicación con mayor carga computacional a la GPU y deja el resto del código ejecutándose en la CPU. Requiere el uso de tarjetas gráficas profesionales de coste bastante elevado, tales como la AMD FirePro W9100, la nVIDIA QUADRO M6000 o la Intel Xeon Phi 7120D.


- La GPU debe tener suficiente memoria para cargar por completo (“in core”) los módulos de NX NASTRAN.
- Aclarar que de momento la GPU Computing no es algo que se pueda utilizar de forma masiva y general en cualquier tipo de cálculo por Elementos Finitos con NX Nastran, es una ayuda que puede reducir el tiempo de cálculo en la resolución de problemas muy específicos, por ejemplo, en el Análisis Dinámico de Respuesta en Frecuencias (SOL111). El impacto en la reducción del tiempo de cálculo es realmente importante en grandes modelos donde sea necesario extraer una gran cantidad de modos de vibración (+5000 modos).
- Hasta ahora la implementación del GPU COMPUTING con NX NASTRAN se ha centrado en dos módulos: DCMP (descomposición de la matriz) y FRRD1 (respuesta en frecuencia).
- En pruebas realizados por Joe Bracking (miembro del equipo de desarrollo de FEMAP en EE.UU.) sobre un ordenador Dell T3600 con procesador Xenon dual, quad core, 64 GB de RAM, 1TB hybrid drive, 512GB SSD drive, 256GB PCIe SSD drive y una tarjeta gráfica AMD Firepro W9100 con 16 GB demuestran que la implementación del módulo DCMP en Windows parece que no funciona muy bien (en Linux hace bien el trabajo), emplea más tiempo de cálculo en vez de reducirlo.
- En cambio la implementación del módulo FRRD1 trabaja muy bien cuando se usa con una tarjeta gráfica potente. La buena noticia es que en el nuevo interface de usuario de FEMAP V11.3 podremos activar de forma selectiva únicamente el módulo FRRD1 en vez de dejar que NX NASTRAN utilice ambos módulos con la GPU. De todas formas la tecnología cambia rápidamente y en muy en pocos meses, y todo aquello que antes era imposible de pronto se puede hacer realidad, así que estaremos atentos a la evolución del mercado.

Priorizar para obtener máximas prestaciones al menor precio
- Maximizar el nº de cores cuanto más rápidos mejor y con la mayor cantidad de memoria caché.
- Añadir toda la memoria RAM posible.
- Maximizar el rendimiento I/O y la velocidad del disco.
- Añadir aceleración de cálculo por GPU en cálculos dinámicos de grandes modelos.
Sistema Operativo (SO): I/O Cache
Problema
- La lectura y escritura de información en el disco duro es lenta en discos mecánicos.
- Algunos sectores del disco se leen varias veces de forma repetida.
- La información que se escribe en el disco probablemente se vaya a leer de nuevo muy pronto.
Solución
- Mantener la información en memoria reducirá los tiempos de búsqueda en el disco.
- Hacer uso de la memoria RAM libre como memoria caché.
- Cuando una aplicación necesita memoria, el gestor de memoria caché pagina memoria al disco (Paginar la apllicación vs. Paginar el I/O Cache).
SO: Habilitar “I/O Cache” en el Disco
- La caché de lectura está siempre habilitada por defecto tanto en Linux como en Windows (superfetch feature).
- En Linux la caché de escritura se habilita usando la orden “hdparm” o equivalente.
- En Windows ir a “Panel de Control > Sistema > Configuración Avanzada del Sistema > Hardware > Administración de Dispositivos > Unidades de Disco > Directivas” para habilitar la caché de escritura en los diferentes dispositivos de almacenamiento.

I/O Cache & Paginación en Windows
Problema
- A medida que un fichero se hace más y más grande, el SO se queda sin memoria.
- El gestor de memoria caché del SO paginará a disco la última memoria no utilizada.
- Las páginas de NX NASTRAN se pueden paginar a disco para acomodar la caché de I/O.
Solución
- Limitar el caché de I/O de Windows al 25% – 50% de la memoria física.
- Deshabilitar el caché usando “sysfield=buffio=yes,raw=yes” en el fichero *.rcf.

NX Nastran: Memoria RAM
Fichero *.rcf
Lo primero constatar que en base a las pruebas realizadas puedo asegurar que la última versión de NX Nastran V10.2 es un 10% más rápido que NX Nastrran V10.0 resolviendo exactamente el mismo modelo, lo cual es una excelente noticia. También estoy muy contento con el nuevo fichero de configuración (*.rcf) implantado a partir de la versión de NX Nastran V10.0. Por si no lo hebeis notado el nuevo fichero de configuración nast10.rcf incluye detalles muy interesantes que ayudan al usuario a sacar más provecho fácilmente de las máquinas con mucha memoria RAM. Los nuevos parámetros también ayudan a evitar que un usuario asigne recursos excesivos que ocasionen una pérdida de prestaciones. Aquí tienes copia del fichero nast10.rcf:
buffsize=32769
memory=.45*physical
smem=20.0X
buffpool=20.0X
Se recomienda consultar el fichero *.F04 para ver si hemos definido los parámetros de cálculo óptimos para el modelo.
- Asignar al cálculo suficiente memoria RAM para evitar que el solver pagine a disco (avoid disk spillover).
- Al menos asignar 1.2 a 1.3 veces el valor que aparece en “memory required to avoid spill“
- No asignar a NX Nastran más del 50% de la memoria total del sistema. De esta forma el SO tendrá más memoria RAM libre para convertirla en I/O Cache y acelerar el proceso de cálculo.
- Cuando no hay memoria RAM suficiente esto puede afectar al método de re-ordenación usado en NX Nastran provocando una descomposición muy lenta de la matriz de rigidez. Asegúrate de seleccionar bien el método BEND o el método METIS.

La siguiente imagen muestra el tiempo de cálculo de diferentes modelos de EF resueltos con NX Nastran en función de la memoria RAM disponible:

- Incluso cuando la memoria RAM es suficiente para descomponer la matriz de rigidiez, otros módulos de NX Nastran como MPYAD pueden dar múltiples pases cuando la memoria es insuficiente, lo cual genera más I/O (revisar siempre el fichero *.F04).

NX Nastran: Directorio “Scratch”
![]() Es crítico situar correctamente el directorio “Scratch” de NX Nastran: usar el “keyword” SDIRECTORY (o abreviado SDIR) en el fichero <femar_dir>\nastran\conf\nast10.rcf, por ejemplo:
Es crítico situar correctamente el directorio “Scratch” de NX Nastran: usar el “keyword” SDIRECTORY (o abreviado SDIR) en el fichero <femar_dir>\nastran\conf\nast10.rcf, por ejemplo:
Sdir=C:\SCRATCH
program=FEMAP
scr=yes
buffsize=32769
memory=.45*physical
smem=20.0X
buffpool=20.0X
- El directorio SCRATCH debe estar situado en un disco rápido (por ejemplo un disco SSD PCI-Express) o en una matriz de discos configurados en modo RAID-0 (lo ideal es un RAID-0 a base de discos SSD).
- Siempre es preferible un disco local frente a una red (usando una conexión Infiniband o GigE dedicada).
- Un directorio SCRATCH situado en una red local genérica con un sistema de archivos NFS tendrá una penalización significativa en prestaciones debido a su I/O lento que afectará a la red local general.
En FEMAP la orden FILE > PREFERENCIAS > DATABASE te permite controlar la dirección del directorio SCRATCH para FEMAP (recuerda, este valor corresponde a FEMAP, no a NX NASTRAN), pero yo utilizo el mismo directorio para ambos ya que las exigencias en cuanto a prestaciones son las mismas: una unidad de disco lo más rápida posible!!.

En FEMAP la orden FILE > PREFERENCES > INTERFACES nos permite especificar la dirección del directorio SCRATCH de NX Nastran: “0..Nastran Default” significa que usará la variable SDIR del fichero *.rcf.

NX Nastran: Procesado en Paralelo
Actualmente con NX Nastran tenemos disponibles dos tipos de arquitecturas para cálculo en paralelo:SMP y DMP.
- La arquitectura SMP (Shared Memory Parallel) permite asignar tantos CORES como tenga el ordenador para realizar el cálculo en paralelo con NX NASTRAN, pero no es escalable y tiene sus limitaciones a partir de un cierto nº de cores.
- En cambio, la arquitectura DMP (Distributed Memory Parallel) permite utilizar un CLUSTER de múltiples máquinas con uno o más procesadores comunicadas a través de una red local, donde cada máquina tiene su propia memoria RAM y su disco duro, por tanto la solución es escalable, una bomba!!.

La siguiente imagen muestra las diferencias entre ambas arquitecturas de cálculo en paralelo: SMP vs. DMP.

NX Nastran SMP
- Fácil de usar: simplemente en FEMAP especificamos el nº de CORES y listo!.
- Disponible en todos los tipos de análisis de NX NASTRAN.
- Módulos de NX Nastran paralelizados:
- Matrix decomposition, DCMP
- Multiply Add, MPYAD
- Forward-Backward Substitution, FBS
- (Frequency response, FRRD1
- Driver module for Sol 401 (NLTRD3)
- Resto de módulos que indirectamente hagan llamadas a DCMP, MPYAD, FBS.

NX Nastran DMP
- Disponible con los siguientes tipos de análisis SOL101, SOL103, SOL105, SOL108, SOL111, SOL112 y SOL200.
- Partición de la malla, Frecuencias y Cargas.
- Disponible tanto en plataformas Linux x86_64 como en Windows.
- El módulo DMP estará disponible como add-on con FEMAP V11.3 y NX Nastran Desktop.

NX Nastran: Análisis Lineal de Contactos
Importancia de la Máxima Distancia de Contacto

- NX Nastran soporta contacto lineal en análisis estático lineal (SOL101), así como en análisis de frecuencias y modos de vibración (SOL103), pandeo lineal (SOL105), dinámico de frecuencias (SOL111) y dinámico transitorio (SOL112). También incluye la capacidad de contacto en análisis no lineal estático y dinámico con el nuevo solver “multi-step” SOL401.
- Las opciones de contacto son:
- “superficie-a-superficie” entre caras de elementos Shell y Sólidos 3-D.
- “arista-con-arista” en problemas Sólidos 2-D de tensión plana, deformación plana y axisimétricos (sólidos de revolución).
- Hay que poner mucha atención al valor de la máxima distancia de contacto (Maximum Contact Search Distance) ya que influye de manera importante en el nº de iteraciones de contacto y por tanto en el tiempo total de cálculo.
- El rango entre el valor mínimo y máximo de la distancia de búsqueda de contacto lo usa el solver NX Nastran internamente para determinar qué caras (o aristas) de elementos están incluidos en dicho rango y generar los elementos de contacto entre ellos. Estos elementos de contacto se crean únicamente una vez, al inicio del análisis estático lineal SOL101, y se mantendrán los mismos durante todo el análisis, aunque el solver a cada iteración de contacto determinará el status de cada elemento de contacto: entre activo e inactivo.
- Recuérdese que estamos hablando de cálculo estático lineal donde se producen pequeños desplazamientos (small displacements), por tanto las piezas en contacto deben estar tocándose físicamente, no puede existir una separación importante entre componentes, por tanto se debe definir un valor reducido de la distancia de contacto tal como 0.1 mm ó 0.5 mm, que a nadie se le ocurra definir una separación de digamos 5.0 mm entre cuerpos y realizar un análisis de contacto estático lineal porque el resultado obtenido en desplazamientos y tensiones será “useless“, es decir, servirá de bien poco, OK?.
- Se recomienda utilizar el solver Iterativo (Element Iterative Solver) cuando el modelo esté mallado masivamente con elementos 3-D sólidos CTETRA y/o CHEXA. Con elementos 2-D Shell y 1-D Viga se recomienda usar siempre el Direct Sparse Solver (por defecto).
- Ajustar los valores globales de los parámetros MAXF (Maximum Force Iterations = 10, por defecto) y CTOL (Contact Force Convergence Tolerance = 0.01, por defecto) de la tarjeta BCTPARM para reducir el nº de iteraciones de contacto.

El siguiente gráfico muestra la relación entre el nº de iteraciones de contacto y el nº de elementos de contacto que están activos entre una iteración y la siguiente (NCHG) para diferentes valores de la máxima distancia de contacto: cuanto mayor es la distancia de contacto, mayor es el tiempo de cálculo.

Reutilizar la Matriz de Contacto
NX Nastran permite escribir la matriz de contacto en formato DMIG incluyendo el parámetro KGGCPCH=1 en el BULK DATA SECTION (es decir, PARAM, KGGCPCH, 1) del fichero de entrada del análisis estático lineal (SOL101) de NX Nastran. El solver escribe la matriz de rigidez de contacto a partir de la última iteración de contacto en el fichero PUNCH en formato DMIG (Direct Matrix Input at Grids). Esta opción sólo está disponible con el DIRECT SPARSE solver (el solver iterativo no soporta esta opción).
La matriz DMIG se puede incluir en sucesivos análisis incluyendo la siguiente línea en el CASE CONTROL del fichero de entrada de NX Nastran: K2GG = KGGC
Los beneficios que obtenemos son los siguientes:
- Incluir el efecto de contacto en sucesivos análisis tal como análisis de frecuencias (SOL103) o análisis de respuesta forzada (SOL111) sin tener que resolver de nuevo el problema de contacto.
- Ahorro considerable de tiempo de cálculo.

Tornillos Pretensados con Contacto
NX Nastran permite definir tornillos pretensados no sólo con elementos viga 1-D CBEAM sino también mallando con elementos sólidos 3-D CTETRA, CHEXA o CPENTA y definir el contacto local de “no penetración” entre la superficie exterior del tornillo (cabeza, tuerca y bástago) y las superficies de las piezas a unir.
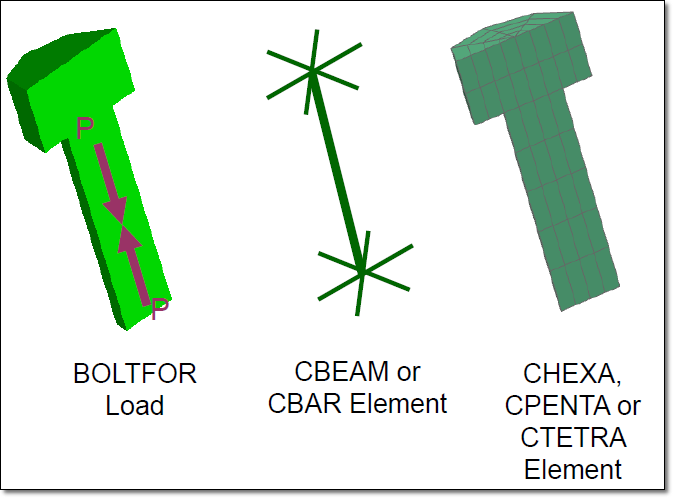 La siguiente imagen muestra un ejemplo de aplicación del contacto entre la cabeza y bástago del tornillo pretensado con las piezas a unir de forma solidaria.
La siguiente imagen muestra un ejemplo de aplicación del contacto entre la cabeza y bástago del tornillo pretensado con las piezas a unir de forma solidaria.

Tornillos Pretensados en un Análisis Modal (SOL103) con Contactos
NX Nastran permite incluir una condición de contacto en un análisis de modos normales (SOL103) a través del comando STATSUB calculando la matriz de rigidez diferencial que incluye la matriz de contacto. Todo esto lo tenéis explicado paso-a-paso en la siguiente publicación (Noviembre 2011): ANÁLISIS DE FRECUENCIAS (SOL103) DE UN ENSAMBLAJE CON CONTACTOS “SURFACE-TO-SURFACE”

Tornillos Pretensados en un Análisis Dinámico de Respuesta Forzada (SOL111) con Contactos
NX Nastran permite incluir también una condición de contacto en un análisis dinámico modal de respuesta en frecuencias (SOL111) o modal transitorio (SOL112) utilizando diferentes técnicas con el mismo resultado. La opción de reutilizar la matriz de rigidez de contacto en formato DMIG es 9 veces más rápida.

En Resumen …
- La selección juiciosa del hardware puede mejorar las prestaciones de forma significativa.
- Maximizar el uso de los recursos hardware eligiendo las opciones adecuadas tanto del SO como del solver NX Nastran:
- Aceleración por la GPU.
- Gestión de Memoria.
- Procesado en Paralelo.
- Parámetros de Contacto.
- Métodos de Solución.
Saludos,
Blas.


Hi Blas,
Excellent article, congrats!
Is Intel Optane Memory 16 GB useful for FEA?
Or, Is a better choice to use the M.2 slot to put an SSD M.2 NVME Samsung 970 EVO (3.400 MB/s)?
Thank you!
LikeLiked by 1 person
Dear Fernando,
For FEA the RAM memory is critical, if not enough RAM available forget the faster processor or SSD speed, is useless, if not a minimum RAM available the solver will have to use the hard disc to make calculations instead to run in memory.
For serious FEA users a minimum of 32 GB is required (I have 128 GB RAM DDR4 at 3000 MHz), and of course the samsung 970 EVO is critical as well for nastran SCRATCH, highly recommended!! (I have two SSD 970 PRO PCIe 1 TB each).
Best regards,
Blas.
LikeLike
Thank you Blas!
LikeLike
Hi Blas,
thank you for article. Are memory with ECC needed for implicit FEA?
Thank you.
LikeLike
Hello!,
In my opinion ECC memory compared with non-ecc memory is not the question, the first issue is to have enough RAM memory to run the solver fully in core, if not the NX NASTRAN solver will use hard disc space, then performance will be very low.
The key here is to install faster RAM memory DDR4 at minimum 3000 MHz, even better 3600 MHz with low latency, expensive, yes.
Best regards,
Blas.
LikeLike